Архив интернета
Содержание:
- Что такое веб-архив и зачем он нужен?
- Проекты
- Мнения в Сторис
- Как узнать историю сайта? Пошаговая инструкция
- Индексация веб-страниц в интернете
- Методы сбора
- Качаем сайт с web-arhive.ru
- Аспекты архивирования
- Качаем сайт с web.archive.org
- Восстановление сайта без «бэкапа» и поиск нужного архива
- Компании, архивирующие интернет
- Как найти архивные копии сайтов интернета Копилка эффективных советов
- Как пользоваться веб-архивом?
- Как использовать веб-архив?
- Блокировка Архива Интернета
- Борьба с добром и российской судебной практикой
- Уникальный контент из «мертвых» сайтов
Что такое веб-архив и зачем он нужен?

Веб-архив — история миллионов сайтов Веб-архив — это специализированный сайт, который предназначен для сбора информации о различных интернет-ресурсах. Робот осуществляет сохранение копии проектов в автоматическом и ручном режиме, все зависит лишь от площадки и системы сбора данных.
На текущий момент имеется несколько десятков сайтов со схожей механикой и задачами. Некоторые из них считаются частными, другие — открытыми для общественности некоммерческими проектами. Также ресурсы отличаются друг от друга частотой посещения, полнотой сохраняемой информации и возможностями использования полученной истории.
Как отмечают некоторые эксперты, страницы хранения информационных потоков считаются важной составляющей Web 2.0. То есть, частью идеологии развития сети интернет, которая находится в постоянной эволюции
Механика сбора весьма посредственная, но более продвинутых способов или аналогов не имеется. С использованием веб-архива можно решить несколько проблем: отслеживание информации во времени, восстановление утраченного сайта, поиск информации.
Проекты
Wayback Machine
Логотип Wayback Machine
The Wayback Machine — веб-сервис Архива. Содержание веб-страниц время от времени фиксируется c помощью бота или при ручном указании посетителем сайта адреса страницы для фиксации. Таким образом, можно посмотреть, как выглядела та или иная страница раньше, даже если она больше не существует.
Легальность
На сервис не раз подавались судебные иски в связи с тем, что публикация контента может быть нелегальной. По этой причине сервис удаляет материалы из публичного доступа по требованию их правообладателей или, если доступ к страницам сайтов не разрешён в файле robots.txt владельцами этих сайтов.
Книга, изготовленная в течение 20 минут в рамках проекта Book-on-demand, на основе электронной книги из Архива
В 2002 году часть архивных копий веб-страниц, содержащих критику саентологии, была удалена из архива с пояснением, что это было сделано по «просьбе владельцев сайта». В дальнейшем выяснилось, что этого потребовали юристы Церкви саентологии, тогда как настоящие владельцы сайта не желали удаления своих материалов. Некоторые пользователи сочли это проявлением интернет-цензуры.
Сервис веб-архива может использоваться в качестве меры борьбы с блокировками доступа к сайтам: как и сервис кэшированных копий страниц от поисковых систем, Архив Интернета позволяет ознакомиться с более ранними копиями популярных страниц. Однако использование Архива и кэшей в таких целях требует специальных усилий от пользователя и позволяет получить доступ не ко всем сайтам.
Open Library
Основная статья: Open Library
Книжный сканер Архива
Open Library — общественный проект по сканированию всех книг в мире, к которому приступила Internet Archive в октябре 2005 года. На февраль 2010 года библиотека содержит в открытом доступе 1 миллион 165 тысяч книг, в каталог библиотеки занесено больше 22 млн изданий. По данным на 2008 год, Архиву принадлежат 13 центров оцифровки в крупных библиотеках. По оценке Internet Archive на ноябрь 2008 года, коллекция составила более 0,5 петабайта, включая изображения и документы в формате PDF. Коллекция постоянно растёт, так как библиотека сканирует около 1000 книг в день.
Scan-on-demand — бесплатная оцифровка желаемых публикаций из фондов Бостонской общественной библиотеки, относится к проекту «Открытая библиотека».
Собрание фильмов, аудио, текстов и программного обеспечения, которые являются общественным достоянием или распространяются под лицензией Creative Commons.
Мнения в Сторис
Создатели социальной сети стараются вносить изменения и новые опции ВК, чтобы пользователям было интересно и весело. Теперь каждый может воспользоваться опцией мнения в сторис. Это функция позволяет выразить собственное мнение относительно того или иного вопроса, процесса, новости. Также можно другим юзерам, своим подписчикам. Чтобы воспользоваться такой опцией нужно:
- Открыть новости, где доступны сторис.
- Далее нажимаем на создание новой публикации.
Создаем новую публикацию
- Делаем селфи или же добавляем другое изображение.
- Жмем на кнопку в виде наклейки.
- Кликаем на стикер мнения.
- Из представленного перечня нужно выбрать тот, который вас заинтересовал, и вводим вопрос.
Такая история также будет храниться в архиве социальной сети, и при желании вы сможете ее просмотреть. После того как юзеры выберут ее, появится форма для ввода ответа на вопрос. Отвечающий при желании может указать имя или же остаться анонимом.
Как узнать историю сайта? Пошаговая инструкция
Есть ли история у интернет-сайтов? Есть сервисы и инструменты, которые позволяют узнать историю для большинства сайтов.
Как же нам узнать и посмотреть своими глазами историю интересного нам сайта? Ответ вы узнаете из этой статьи.
Интернет – это динамическая среда, в которой все меняется очень быстро. Так, у доменных имен могут меняться их владельцы, обновляться или даже полностью меняться контент сайта, его дизайн, разметка, функциональность. Стоит пустить сайт на самотек – и он уже через пару лет сильно устареет.
Благодаря одному интересному инструменту мы можем узнать историю, отправившись в прошлое, будто бы на машине времени.
Вебархив – www.archive.org
Это интернет-сайт, который индексирует сайты, делает снимки их состояния в разное время и кладет их на свои полки архива, то есть на жесткие диски.
Интересно узнать историю Google.com? Это сделать очень просто – заполняем и смотрим:
История поисковика Google уходит своими корнями в далекий по меркам интернета 1998 год. Посмотрим как он выглядел тогда:
Вот такой вид имела поисковая система Google в то время. Посмотрим еще на любимый Яндекс примерно в то же время:
Любой популярный сайт, как правило, архивируется подобным образом, так что любой желающий может пострадать ностальгией и вспомнить, как давным-давно выглядели его любимые сайты.
Разумеется, сохранить всю историю всех сайтов невозможно, но тем не менее, в базе данных веб архива насчитывается более 450 000 000 сайтов. Архив может быть полезен в самых разных случаях и, кроме того, он абсолютно бесплатен!
Если нужно узнать хронологию сайта, то сервис незаменим, так как можно:
1. Определить тематику усиленного имени и сайта
С помощью веб архива мы сможем увидеть контент, который был на сайте этого домена, а значит – распознать тематику ресурса.
2. Узнать историю сайта
Частно начинающие вебмастеры забрасывают свои сайты, недооценивая их потенциал. А опытные веб-мастеры просто охотятся на такие домены с хорошей историей, чтобы создать на них сайты. Одним из инструментов, который они используют для анализа истории и содержания старого сайта является веб архив.
Поэтому не стоит пренебрегать возможностями, которые нам предоставляет веб архив. Ведь применяя этот инструмент, можно извлечь достаточно много полезной информации о сайте, в том числе просмотреть контент старого сайта.
Индексация веб-страниц в интернете
Начиная с 1996 года по настоящее время на сайте archive.org собрано более 466 миллиардов веб-страниц (эта цифра все время увеличивается). Архив страниц интернета создан для сохранения, ознакомления и изучения имеющей информации, которая накопилась за все эти годы во всемирной сети.
Время от времени, специальные роботы, принадлежащие сервису, индексируют содержание практически всех сайтов в интернете
Следует принять во внимание, что во время обхода робота для индексации сайтов, на некоторых сайтах могли возникать внутренние проблемы: сайт, или некоторые страницы сайта были недоступны, сайт находился на техобслуживании, не работали подключаемые внешние элементы и т. д
Поэтому некоторые архивы сайтов будут полными, а некоторые снимки (архивы) могут содержать только частичную информацию. Имейте в виду, что некоторые сайты индексируются часто, другие сайты, наоборот, довольно редко.
Для просмотра веб-страниц используется онлайн сервис The Wayback Machine. В Internet Archive доступны для просмотра не только действующие в настоящий момент сайты, но и сайты, которые уже не существуют. С помощью архива интернета можно побывать на прекративших существование сайтах, и ознакомится с содержимым веб-страниц удаленных сайтов.
Благодаря замечательному архиву сайтов интернета можно проследить историю изменений, как изменялся внешний облик сайта и его содержимое с течением времени, использовать архивы для восстановления сайта, искать необходимую информацию.
На главной странице сайта archive.org можно получить доступ к архивным данным, которые сгруппированы в тематические разделы, или сразу перейти на страницу сервиса Wayback Machine.
Методы сбора
Существует несколько способов архивирования интернета, ниже описана часть из них.
Удалённый сбор
Метод веб-архивирования отдельных сайтов, автоматизирующий сбор веб-страниц.
Примеры веб-сканеров для персональных компьютеров:
- Heretrix
- HTTrack
- Wget
Онлайн-сервисы веб-сканеров:
- Wayback Machine
- WebCite
Архивирование баз данных
Метод веб-архивирования, который основан на архивированию основного содержания сайта из базы данных.
Таким образом работают системы DeepArc и Xinq, разработанные Национальной библиотекой Франции и Национальной библиотекой Австралии, соответственно. Первая программа позволяет, используя реляционную базу данных, отображать информацию в виде XML-схемы; вторая программа позволяет запомнить оригинальное оформление сайта, соответственно создавая точную копию.
Архивирование транзакциями
Метод архивирования, который сохраняет данные, пересылаемые между веб-сервером и клиентом. Используется, как правило, для доказательств содержания, которое было предоставлено на самом деле в определённую дату. Такое программное обеспечение может потребоваться организациям, которые нуждаются в документировании информации такого типа.
Такое ПО, как правило, просто перехватывает все HTTP-запросы и ответы, фильтруя дубликаты ответов.
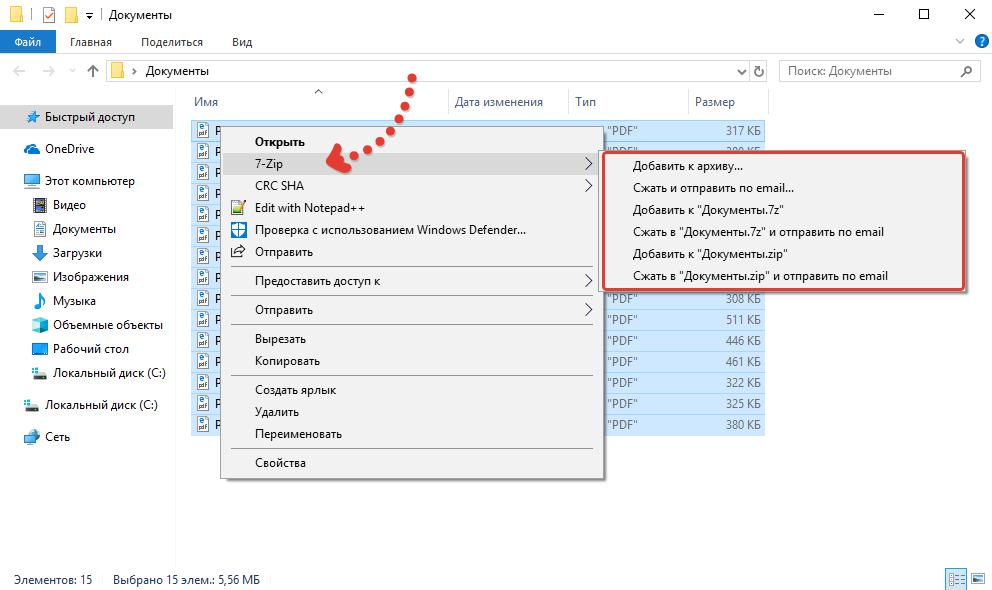
Качаем сайт с web-arhive.ru
Это самый геморройный вариант ибо у данного сервиса нет возможности скачать сайт как у описанного выше. Соответственно пользоваться этим вариантом есть смысл пользоваться только в случае если нужно скачать сайт, которого нет на web.archive.org. Но я сомневаюсь что такое возможно. Этим вариантом я пользовался по причине того, что не знал других вариантов,а поискать поленился.
В итоге я написал скрипт, который позволяет скачать архив сайта с web-arhive.ru. Но велика вероятность того, что это будет сопровождаться ошибками, поскольку скрипт сыроват и был заточен под скачивание определенного сайта. Но на всякий случай я выложу этот скрипт.
Вот ссылка: https://yadi.sk/d/zoMRxwPoSXh0Jw
Пользоваться им довольно просто. Для запуска скачивания необходимо запустить этот скрипт все в той же командной строке, где в качестве параметра вставить ссылку на копию сайта. Должно получиться что-то типа такого:
php get_archive.php «http://web-arhive.ru/view2?time=20160320163021&url=http%3A%2F%2Fremontistroitelstvo.ru%2F»
Заходим на сайт web-arhive.ru, в строке указываем домен и жмем кнопку «Найти». Ниже должны появится года и месяцы в которых есть копии.
Обратите внимание на то, что слева и справа от годов и месяцев есть стрелки, кликая которые можно листать колонки с годами и месяцами
Остается найти дату с нужной копией, скопировать ссылку из адресной строки и отдать её скрипту. Не забывает помещать ссылку в кавычки во избежание ошибок из-за наличия спецсимволов.
Мало того, что само скачивание сопровождается ошибками, более того, в выбранной копии сайта может не быть каких-то страниц и придется шерстить все копии на предмет наличия той или иной страницы.
Аспекты архивирования
Веб-архивирование, как и любой другой вид деятельности, имеет юридические аспекты, которые необходимо учитывать в работе:
- Сертификация в надёжности и целостности содержания веб-архива.
- Сбор проверяемых веб-активов.
- Предоставление поиска и извлечения из массива данных.
- Сопоставимость содержания коллекции
Ниже представлен набор инструментов, который использует Консорциум по архивированию интернета
- Heretrix — архивация.
- NutchWAX — поиск коллекции.
- Открытый исходный код «Wayback Machine» — поиск и навигация.
- Web Curator Tool — выбор и управление.
Другие инструменты с открытым исходным кодом для манипуляций над веб-архивами:
WARC-инструменты — для программного создания, чтения, анализа и управления веб-архивами.
Просто бесплатное ПО:
- Инструменты поиска Google — для полнотекстового поиска.
- WSDK — набор утилит, Erlang-модулей для создания WARC-архива.
Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
http://web.archive.org/web/*/1mds.ru
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:
Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:
Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:
Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.
Долистал я до 23 октября 2017-го и вижу уже другое содержимое:
Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:
А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
http://web.archive.org/web/20180330034350/http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта. Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.
Восстановление сайта без «бэкапа» и поиск нужного архива
По архивам можно перемещаться с помощью календарного меню вверху страницы. Синим кружком помечены даты, когда сделаны слепки. Нажав на него, можно увидеть точное время создания слепка и их количество в заданный день. Эта делается во избежание потери информации, поскольку данные в хранилищах со временем могут испортиться, а также отдельные копии могут быть битыми.
Нажав на просмотр любого слепка, вы перейдете на полностью рабочую страницу ресурса. То есть, все внутренние ссылки будут работать. Однако, сервис может неидеально воспроизвести оформление, а также могут исчезнуть некоторые элементы меню. Паниковать не стоит, поскольку код страницы идентичен вашему. Но простым копированием кода восстановить утерянную информацию не удастся. Поскольку веб хранилище само генерирует ссылки внутри каждого слепка, иначе вы бы перешли на актуальную версию, а не на историю сайта.

Чтобы заставить все работать, нужно удалить вступительную часть ссылки. Однако, во избежание рутинной работы сервис имеет инструмент замены внутренних ссылок на оригинальные. Чтобы воспользоваться им, нужно скопировать веб-адрес страницы с нужным слепком и в конце даты добавить конструкцию «id_».
Адрес должен иметь такой вид
Вставляем конструкцию «id_»
https://web.archive.org/web/20090206215515id_/http://football.ua:80/
Далее возвращаем веб-адрес в строку и нажимаем Enter. Очевидно, что восстановление ресурса таким образом займет просто невероятное количество времени. Но когда выхода нет – выбирать не приходится. Чтобы никогда не пользоваться таким неудобным способом восстановления – лучше делайте бэкапы своего сайта по несколько раз в день. Это поможет уберечь ваши нервы от лишнего стресса.
Если вам нужно отобразить все страницы необходимого сайта, введите такой веб-адрес в строку браузера:
На странице, которая открылась, существует возможность отфильтровать файлы по разным форматам.
Компании, архивирующие интернет
Архив Интернета
Основная статья: Архив Интернета
В 1996 году была основана некоммерческая организация «Internet Archive». Архив собирает копии веб-страниц, графические материалы, видео-, аудиозаписи и программное обеспечение. Архив обеспечивает долгосрочное архивирование собранного материала и бесплатный доступ к своим базам данных для широкой публики. Размер архива на 2019 год — более 45 петабайт; еженедельно добавляется около 20 терабайт. На начало 2009 года он содержал 85 миллиардов веб-страниц., в мае 2014 года — 400 миллиардов. Сервер Архива расположен в Сан-Франциско, зеркала — в Новой Александрийской библиотеке и Амстердаме. С 2007 года Архив имеет юридический статус библиотеки. Основной веб-сервис архива — The Wayback Machine. Содержание веб-страниц фиксируется с временны́м промежутком c помощью бота. Таким образом, можно посмотреть, как выглядела та или иная страница раньше, даже если она больше не существует по старому адресу.
В июне 2015 года сайт был заблокирован на территории России по решению Генпрокуратуры РФ за архивы страниц, признанных содержащими экстремистскую информацию, позднее был исключён из реестра.
WebCite
Основная статья: WebCite
«WebCite» — интернет-сервис, который выполняет архивирование веб-страниц по запросу. Впоследствии на заархивированную страницу можно сослаться через url. Пользователи имеют возможность получить архивную страницу в любой момент и без ограничений, и при этом неважен статус и состояние оригинальной веб-страницы, с которой была сделана архивная копия. В отличие от Архива Интернета, WebCite не использует веб-краулеров для автоматической архивации всех подряд веб-страниц. WebCite архивирует страницы только по прямому запросу пользователя. WebCite архивирует весь контент на странице — HTML, PDF, таблицы стилей, JavaScript и изображения. WebCite также архивирует метаданные о архивируемых ресурсах, такие как время доступа, MIME-тип и длину контента. Эти метаданные полезны для установления аутентичности и происхождения архивированных данных. Пилотный выпуск сервиса был выпущен в 1998 году, возрождён в 2003.
По состоянию на 2013 год проект испытывает финансовые трудности и проводит сбор средств, чтобы избежать вынужденного закрытия.
Peeep.us
Сервис peeep.us позволяет сохранить копию страницы по запросу пользования, в том числе и из авторизованной зоны, которая потом доступна по сокращённому URL. Реализован на Google App Engine.
Сервис peeep.us, в отличие от ряда других аналогичных сервисов, получает данные на клиентской стороне — то есть, не обращается напрямую к сайту, а сохраняет то содержимое сайта, которое видно пользователю. Это может использоваться для того, чтобы можно было поделиться с другими людьми содержимым закрытого для посторонних ресурса.
Таким образом, peeep.us не подтверждает, что по указанному адресу в указанный момент времени действительно было доступно заархивированное содержимое. Он подтверждает лишь то, что у инициировавшего архивацию по указанному адресу в указанный момент времени подгружалось заархивированное содержимое. Таким образом, Peeep.us нельзя использовать для доказательства того, что когда-то на сайте была какая-то информация, которую потом намеренно удалили (и вообще для каких-либо доказательств). Сервис может хранить данные «практически вечно», однако оставляет за собой право удалять контент, к которому никто не обращался в течение месяца.
Возможность загрузки произвольных файлов делает сервис привлекальным для хостинга вирусов, из-за чего peeep.us регулярно попадаёт в чёрные списки браузеров.
Archive.today
Основная статья: archive.today
Сервис archive.today (ранее archive.is) позволяет сохранять основной HTML-текст веб-страницы, все изображения, стили, фреймы и используемые шрифты, в том числе страницы с Веб 2.0-сайтов, например с Твиттер.
Как найти архивные копии сайтов интернета Копилка эффективных советов
Как найти архивные копии сайтов интернета или машина времени для сайтов
Существует настоящая, реальная машина времени, в которой можно ненадолго вернуться в прошлое и увидеть, например, как выглядел тот или иной сайт несколько лет назад. Думаете, никому не нужны копии сайтов многолетней давности? Ошибаетесь! Для очень многих людей сервис по архивированию информации весьма полезен.

Во-первых, это просто интересно! Из чистого любопытства и от избытка свободного времени можно посмотреть, как выглядел любимый, популярный ресурс на заре его рождения.
Во-вторых, далеко не все владельцы сайтов ведут свои архивы
Знать место, где можно найти информацию, которая была на сайте в какой-то момент, а потом пропала, не просто полезно, а очень важно
В-третьих, само по себе сравнение является важнейшим методом анализа, который позволяет оценить ход и результаты нашей деятельности. Кстати, при проведении анализа веб-ресурса очень эффективно использовать ряд методов сравнения.
Поэтому наличие уникальнейшего архива веб-страниц интернета позволяет нам получить доступ к огромному количеству аудио-, видео- и текстовых материалов. По утверждению разработчиков, «интернет-архив» хранит больше материалов, чем любая библиотека мира. Мы попали в правильное место!
Что нужно, чтобы найти копии сайтов интернета
Для того, чтобы отправиться в прошлое, нужно перейти на сайт archive.org и воспользоваться поисковой строкой.
Простой поиск в архиве сохраненных сайтов выдает нам ссылки на все сохраненные копии запрашиваемой страницы.

Из этого скриншота видно, что сайт kopilkasovetov.com был создан в 2012 году (Кстати, важно отметить, с помощью практически идеального хостинга Спринтхост — рекомендую!). Переключаясь на нужный нам год, можно увидеть даты, выделенные кружочками, это и есть даты сохранения копии сайта. Например, в 2015 году, пока можно будет увидеть только одну копию от 7 февраля
Например, в 2015 году, пока можно будет увидеть только одну копию от 7 февраля.
Конечно, это потрясающий ресурс! Ведь здесь индексируются и архивируются все сайты интернета! Это не только скриншоты… Имея в руках такой инструмент, можно восстановить массу потерянной со временем информации.
Надо заметить, что, безусловно все восстановить однозначно не получится, так как если на страницах сайта используются элементы Java Script, или скрипты или графика взяты со стороннего сервера, то на восстановление такой информации рассчитывать не придется
Поэтому к сохранению данных своего сайта нужно относиться с особенным вниманием, несмотря ни на что
Пользуясь случаем, я сделала скриншоты и восстановила в памяти, как выглядел мой сайт, начиная с 2012 года. Любопытно посмотреть))
Сайт буквально недавно «родился»)) Январь 2012…

Проходит время, и хочется что-то изменить… Конец 2012-го.

Наверное, пора уже что-то менять. 2013-й. Это тема, которая и сегодня установлена на моем сайте.

К смене темы отношусь с осторожностью, так как помню последний «переезд», после которого несколько месяцев восстанавливала посещаемость сайта. Как-то не очень удачно получилось. Надеюсь, что и моим читателям эта замечательная интернет-библиотека — «машина времени» сможет помочь перемещаться во времени, когда они этого захотят
Посмотрите, как выглядели раньше некоторые сайты, еще во времена своего зарождения. Какими раньше были google или яндекс, можно увидеть только на archive.org, аналогов у этого ресурса нет. Приятного путешествия, друзья!
Надеюсь, что и моим читателям эта замечательная интернет-библиотека — «машина времени» сможет помочь перемещаться во времени, когда они этого захотят. Посмотрите, как выглядели раньше некоторые сайты, еще во времена своего зарождения. Какими раньше были google или яндекс, можно увидеть только на archive.org, аналогов у этого ресурса нет. Приятного путешествия, друзья!
Как пользоваться веб-архивом?
В том, как пользоваться веб-архивом, нет ничего сложного. Для того, чтобы использовать его, достаточно перейти на соответствующий сайт archive.org и в поиске вести адрес нужного сайта. После непродолжительного времени, архив выдаст информацию об имеющихся сохранениях этого ресурса.
Например, с помощью этого можно найти информацию с сайта, который по каким-либо причинам перестал существовать. Так же веб архив поможет найти информацию со страниц, даже если она была удалена
Это особенно важно для поиска удачных примеров сторителлинга лет. Рассмотрим подробнее, как посмотреть архив.
Как использовать веб-архив?
Форма для поиска информации на Peeep.us
Как уже отмечалось выше, веб-архив — это сайт, который предоставляет определенного рода услуги по поиску в истории. Чтобы использовать проект, необходимо:
- Зайти на специализированный ресурс (к примеру, web.archive.org).
- В специальное поле внести информацию к поиску. Это может быть доменное имя или ключевое слово.
- Получить соответствующие результаты. Это будет один или несколько сайтов, к каждому из которых имеется фиксированная дата обхода.
- Нажатием по дате перейти на соответствующий ресурс и использовать информацию в личных целях.
О специализированных сайтах для поиска исторического фиксирования проектов поговорим далее, поэтому оставайтесь с нами.
Блокировка Архива Интернета
В России
| Внешние изображения |
В октябре 2014 года Роскомнадзор заблокировал на территории РФ доступ к некоторым страницам Архива Интернета за видеоролик «Звон мечей» экстремистской группировки «Исламское государство Ирака и Леванта» (нынешнее название — «Исламское государство»). Ранее блокировались только ссылки на отдельные материалы в архиве, однако 24 октября 2014 года в реестр запрещённых сайтов временно был включён сам домен и его IP-адрес.
16 июня 2015 года на основании статьи 15.3 закона «Об информации, информационных технологиях и о защите информации» генпрокуратура РФ приняла решение о блокировке страницы «Одиночный джихад в России», содержащей, по её мнению, «призывы к массовым беспорядкам, осуществлению экстремистской деятельности, участию в массовых мероприятиях, проводимых с нарушением установленного порядка», в действительности на территории России был заблокирован доступ ко всему сайту, кроме .
С апреля 2016 года Роскомнадзор решил убрать сайт из блокировок, и он доступен в России.
В других странах СНГ
Архив блокировался на территории Казахстана в 2015 году.
Также в 2017 году сообщалось о блокировках архива в Кыргызстане.
В Индии
В Индии Архив был частично заблокирован судебным решением в августе 2017 года. Решение Madras High Court перечисляло 2,6 тыс. адресов в сети Интернет, которые способствовали пиратскому распространению ряда фильмов двух местных кинокомпаний. Представители проекта безуспешно пытались связаться с министерствами.
Борьба с добром и российской судебной практикой
Организация Internet Archive зарегистрирована в Сан-Франциско (Калифорния, США), а одноименный ресурс, согласно законам штата Калифорния, официально считается библиотекой. Организация располагает обширным списком партнеров, в число которых входят многие крупные организации со всего мира. К ним относятся, в частности, Национальный научный фонд США и Библиотека конгресса США
CIO и СTO: как меняется влияние ИТ-руководителей в компаниях?
Новое в СХД
В России «Архив интернета» нередко используется российскими судами как доверенную третью сторону и источники информации, в том числе улик и доказательств расследования.
Уникальный контент из «мертвых» сайтов
Каждый день из интернета исчезают десятки и даже сотни разнообразных сайтов. Стоит отметить, что абсолютное большинство не представляет особой ценности, но в каждой реке можно найти много крупинок золота. Главное, чтобы полезные сайты имели хотя бы один работающий слепок в archive.org.
Поскольку информация из умерших сайтов поступенно перестает индексироваться поисковыми системами, такой контент становится уникальным (конечно, если он не был «сплагиачен» до этого). Выставив эту информацию на свой ресурс, вы станете ее правообладателем или первоисточником для поисковых систем. Главное, предварительно проверить ее на уникальность, чтобы не нарушить ничей копирайт. Но как именно отыскать подобные ресурсы среди гор мусора?
К счастью, существует один способ.
После этого нужно всего лишь просматривать информацию Webarchive с каждого ресурса, который вас заинтересовал. Безусловно, такой метод предполагает наличие внимательности, а также терпения, поскольку качество большинства данного контента будет низкопробным.











 Adblock
Adblock