Руководство по kubernetes, часть 2: создание кластера и работа с ним
Содержание:
- Практика работы с Kubernetes: развёртывания
- Запуск dask кластера
- Туристический кластер, что это
- Кластер – единица хранения данных
- 2. Используйте режим слайд-мастера для обновления дизайна последовательно
- Постановка задачи кластеризации[править]
- Теорема невозможности Клейнберга[править]
- Практическая реализация
- Типология задач кластеризации[править]
- Кластер как метод критического мышления
- Пример кластера в истории
- Уникальный татарстанский проект
- Заключение
Практика работы с Kubernetes: развёртывания
▍Использование развёртываний
Текущее состояние кластера
- Мы хотим иметь возможность создать два пода на основе одного контейнера .
- Нам нужна система развёртывания приложения, позволяющая ему, при его обновлении, работать без перерывов.
- Мы хотим, чтобы подам была бы назначена метка , что позволит обнаруживать эти поды сервису .
▍Описание развёртывания
- : тут указано, что мы описываем ресурс вида .
- : свойство объекта спецификаций развёртывания, которое задаёт то, сколько экземпляров (реплик) подов нужно запустить.
- : описывает стратегию, используемую в данном развёртывании при переходе с текущей версии на новую. Стратегия обеспечивает нулевое время простоя системы при обновлении.
- : это свойство объекта , которое задаёт максимальное число недоступных подов (в сравнении с желаемым количеством подов) при выполнении последовательного обновления системы. В нашем развёртывании, подразумевающем наличие 2 реплик, значение этого свойства указывает на то, что после завершения работы одного пода ещё один будет выполняться, что делает приложение доступным в ходе обновления.
- : это свойство объекта , которое описывает максимальное число подов, которое можно добавить в развёртывание (в сравнении с заданным числом подов). В нашем случае его значение, 1, означает, что, при переходе на новую версию программы, мы можем добавить в кластер ещё один под, что приведёт к тому, что у нас могут быть одновременно запущены до трёх подов.
- : этот объект задаёт шаблон пода, который описываемый ресурс будет использовать для создания новых подов. Вам эта настройка, наверняка, покажется знакомой.
- : метка для подов, создаваемых по заданному шаблону.
- : определяет порядок работы с образами. В нашем случае это свойство установлено в значение , то есть, в ходе каждого развёртывания соответствующий образ будет загружаться из репозитория.
▍Выполнение развёртываний с нулевым временем простоя системы
Замена подов в ходе обновления системы
Запуск dask кластера
Процесс-планировщик создается один на кластер. Запускать его можно на любой машине. Единственная очевидная рекомендация — машина должна быть максимально доступна.
Процессы-работники запускаются на всех компьютерах, ресусами которых вы планируете пользоваться.
- / — количество процессов, которые будут запущены, и количество потоков в каждом из них. Поскольку GIL присутствует и на стороне процессов-работников, запускать обработку на многих потоках имеет смысл только если распределенный процесс реализован на чем-то низкоуровневом, как numpy. В противном случае нужно масштабироваться за счет количества процессов.
- — объем памяти, доступный каждому процессу. Ограничивать доступную память процесам нужно очень аккуратно — при достижении предела по памяти процесс-работник перестартовывает, что может вызвать остановку процесса обработки. Я сначала ставил ограничение, но потом убрал.
- — время в секундах, в течении которого процессы-работники будут ждать, пока планировщик перезапустится. Это время нужно подбирать в соответствии с ожидаемым временем перезагрузки компьютера-планировщика. Как ни странно, похоже, этот параметр не всегда учитывается.
- — префикс имени процесса-работника, как он будет отображаться в отчетах планировщика. Это удобно, чтобы видеть «человеческие» имена сервисов-работников.
- — директория, которая будет использоваться для создания временных файлов
Запуск процессов-работников на Windows в виде сервиса
Понятно, что запуск dask-worker со всему параметрами делается в виде пакетного файла. Также, чтобы кластер поднимался сам, dask-worker должен запускаться как только компьютер стартовал.
NSSM, в частности, позволяет настроить рестарт пакетного файла, в случае его завершения. Это удобно для обработки ситуации, когда планировщик недоступен в течение длительного времени, и процессы-работники завершаются и останавливаются. В этом случае NSSM просто будет их перезапускать.
Также NSSM позволяет перенаправить консольный вывод из пакетного файла в ротируемый файл журнала. Бывает удобно для «разбора полетов»
Проверка Firewall
Также необходимо проверить правила firewall: планировщик должен иметь возможность достучаться до процесса-работника.
Неприятно, что если на узле, где запущен процесс-работник, блокируются входящие соединения — то об этом станет известно только при запуске приложения. В этом случае, если даже до одного узла не получится достучаться — весь клиентский процесс упадет. До этого будет казаться, что все в порядке, поскольку все узлы будут выглядеть как подключенные.
По умолчанию каждый процесс-работник открывает случайный порт. При запуске можно указать прослушиваемый порт, однако в этом случае будет запустить только один процесс.
Туристический кластер, что это
Выяснив, что такое кластер, дать определение кластера в сфере туризма не составит больших сложностей.
Все очень просто. Создание таких кластеров направлено, в первую очередь, на конкурентоспособность в этой сфере.
Основой является управляющая компания, которая регулирует работу туристических операторов, агентств по предоставлению туристических услуг, а также организаций, осуществляющих услуги по размещению гостей — отели, пансионаты, санатории и пр.
Если рассматривать этот кластер далее. То можно обнаружить такие подразделения, как компании по организации трансферта, предприятия питания (рестораны, кафе, бары и т. д.), места досуга и отдыха (парки, спортивные залы, площадки, кинотеатры), торговые точки с сувенирной продукцией.
Таким образом, более расширенное понятие туристского кластера будет выглядеть так:
Кластеры, по видам туристических ресурсов, делятся на водные (морской, речной, озерный), лесные, горные и смешанные. По видам туристских аттракторов они бывают музейные, развлекательные, спортивные, экологические, этнографические, санаторно-курортные и пр. кластеры.
По масштабу выделяют локальные, региональные, национальные и транснациональные кластеры.
Кластер – единица хранения данных
Наиболее часто с понятием «кластер» пользователи компьютера сталкивается при форматировании флешки, диска либо какого-нибудь другого носителя информации.
На рисунке диалоговые окно форматирования диска на операционной системе Windows 7. Это окно практически не отличается в разных ОС семейства Windows.
В диалоговом окне мы видим, что один из параметров форматирования носит название «Размер кластера»
Давайте вместе разберемся, что такое кластер и зачем так важно определять его размер
Начнём того, что файл на диск записывается небольшими частями, эти части совсем не обязательно идут друг за другом, порой они раскиданы по всему диску. Удаляя файл, мы очищаем эти части от информации, записывая — мы заполняем их снова. Понятно, что записывая и удаляя файлы, мы как бы перемешиваем информацию на диске.
Чтобы прочитать файл, жесткому диску приходится считывать её из с разных участков своей памяти. Думаю, понятно, что считывание информации с различных областей диска может существенно замедлять работу системы, ведь гораздо проще считывать информацию последовательно, чем прыгать с места на место.
Понятие кластер, в нашем случае, как раз и относится к этим участкам носителя информации. Кластер – это участки памяти на диске, имеющие определенный заданный объем, являющийся минимальным для хранения файлов.
Чем больше кластер, тем меньше переходов совершит система при считывании информации и тем быстрее будет работать система. Но не все так просто, как кажется на первый взгляд! Кластер может быть занят данными только из одного файла и если даже файл по своему объёму меньше размера кластера, то фактически он будет занимать размер целого кластера. Если размер файла, разделить на размер кластера, то остаток от деления все равно займется одним кластером. Таким образом, возникает дилемма, чем жертвовать — скоростью работы или свободным местом на жёстком диске.
2. Используйте режим слайд-мастера для обновления дизайна последовательно
Большинство моих любимых функций PowerPoint не только экономят время, но также обеспечивают последовательность слайдов. Это огромное преимущество, если логотип находится в одном месте на каждом слайде, например.
Мастер слайдов одновременно управляет дизайном для нескольких слайдов. При настройке мастера слайдов, каждый слайд, который использует этот мастер будет иметь те же изменения.
Перейдите на вкладку «Вид» и выберите «Слайд-мастер». Теперь добавьте что-то, что вы хотите отобразить на каждом слайде (например, текст логотипа или нижнего колонтитула) мастеру:
На верхнем скриншоте я добавил логотип в мастер слайдов, Вы можете увидеть, как он добавляется к нескольким слайдам в одном и том же месте.
Когда вы вернетесь в обычный режим просмотра, вы увидите изменения на каждом слайде, который использует один и тот же мастер.
Опять же: речь идет о создании чистых слайдов с последовательностью. Настройка слайд-мастера — это преимущество производительности и превосходного дизайна.
Постановка задачи кластеризации[править]
Пусть — множество объектов, — множество идентификаторов (меток) кластеров.
На множестве задана функция расстояния между объектами .
Дана конечная обучающая выборка объектов .
Необходимо разбить выборку на подмножества (кластеры), то есть каждому объекту сопоставить метку ,
таким образом чтобы объекты внутри каждого кластера были близки относительно метрики , а объекты из разных кластеров значительно различались.
| Определение: |
| Алгоритм кластеризации — функция , которая любому объекту ставит в соответствие идентификатор кластера . |
Множество в некоторых случаях известно заранее, однако чаще ставится задача
определить оптимальное число кластеров, с точки зрения того или иного критерия качества кластеризации.
Кластеризация (обучение без учителя) отличается от классификации (обучения с учителем) тем,
что метки объектов из обучающей выборки изначально не заданы, и даже может быть неизвестно само множество .
Решение задачи кластеризации объективно неоднозначно по ряду причин:
- Не существует однозначного критерия качества кластеризации. Известен ряд алгоритмов, осуществляющих разумную кластеризацию «по построению», однако все они могут давать разные результаты. Следовательно, для определения качества кластеризации и оценки выделенных кластеров необходим эксперт предметной области;
- Число кластеров, как правило, заранее не известно и выбирается по субъективным критериям. Даже если алгоритм не требует изначального знания о числе классов, конкретные реализации зачастую требуют указать этот параметр;
- Результат кластеризации существенно зависит от метрики. Однако существует ряд рекомендаций по выбору метрик для определенных классов задач..
Число кластеров фактически является гиперпараметром для алгоритмов кластеризации. Подробнее про другие гиперпараметры и их настройку можно прочитать в статье.
Теорема невозможности Клейнберга[править]
Для формализации алгоритмов кластеризации была использована аксиоматическая теория. Клейнберг постулировал три простых свойства в качестве аксиом кластеризации и доказал теорему, связывающую эти свойства.
| Определение: |
| Алгоритм кластеризации является масштабно инвариантным (англ. scale-invariant), если для любой функции расстояния и любой константы результаты кластеризации с использованием расстояний и совпадают. |
Первая аксиома интуитивно понятна. Она требует, чтобы функция кластеризации не зависела от системы счисления функции расстояния и была нечувствительна к линейному растяжению и сжатию метрического пространства обучающей выборки.
| Определение: |
| Полнота (англ. Richness). Множество результатов кластеризации алгоритма в зависимости от изменения функции расстояния должно совпадать со множеством всех возможных разбиений множества объектов . |
Вторая аксиома утверждает, что алгоритм кластеризации должен уметь кластеризовать обучающую выборку на любое фиксированное разбиение для какой-то функции расстояния .
| Определение: |
Функция расстояния является допустимым преобразованием функции расстояния , если
|
| Определение: |
| Алгоритм кластеризации является согласованным (англ. consistent), если результат кластеризации не изменяется после допустимого преобразования функции расстояния. |
Третья аксиома требует сохранения кластеров при уменьшении внутрикластерного расстояния и увеличении межкластерного расстояния.
| Примеры преобразований с сохранением кластеров | ||
| Исходное расположение объектов и их кластеризация | Пример масштабной инвариантности. Уменьшен масштаб по оси ординат в два раза. | Пример допустимого преобразования. Каждый объект в два раза приближен к центроиду своего класса. Внутриклассовое расстояние уменьшилось, межклассовое увеличилось. |
Исходя из этих аксиом Клейнберг сформулировал и доказал теорему:
| Теорема (Клейнберга, о невозможности): |
| Для множества объектов, состоящего из двух и более элементов, не существует алгоритма кластеризации, который был бы одновременно масштабно-инвариантным, согласованным и полным. |
Несмотря на эту теорему Клейнберг показал,
что иерархическая кластеризация по методу одиночной связи с различными критериями останова удовлетворяет любым двум из трех аксиом.
Практическая реализация
В качестве примера такого подхода к реализации проектов подобного рода рассмотрим систему, разработанную компанией «Версия» и предназначенную для применения в тех случаях, когда требуется безотказный непрерывный доступ к данным по формуле 24×7×365 с нулевым временем простоя.
Этот вычислительный комплекс выбран не случайно, поскольку при его разработке было принято решение о создании системы высокой готовности, к тому же удовлетворяющей всем требованиям отказоустойчивости. Также обязательным требованием было наличие возможности гибкого масштабирования с расчетом не только создания любой конфигурации, но и адаптивного расширения функциональности после интеграции системы в существующую инфраструктуру.
Таким образом, при разработке заранее предусматривалась возможность обслуживания и профилактики системы без ее останова, конфигурация просчитывалась с учетом потенциальных точек отказа и обязательного их устранения. Во всех модулях применялось дублирование жизненно важных узлов, сочетаемое с возможностью перехвата управления: в нормальном режиме каждый контроллер выполняет свои функции с подчиненными узлами, но при выходе из строя одного из них второй контроллер будет обслуживать все остальные узлы до замены первого.
Ядром вычислительной системы стал сервер ВЕРСИЯ SP-4000. Он поддерживает до четырех 64-разрядных процессоров Intel Itanium 2 с тактовой частотой до 1,6 GHz (кэш-памятью третьего уровня до 9 МВ), до 32 GB оперативной памяти и до трех жестких дисков SCSI. Высокий уровень отказоустойчивости данной модели достигается резервированием компонентов сервера – блоков питания, вентиляторов, жестких дисков.
Все эти компоненты допускают возможность осуществления замены без выключения сервера (hot-plug); кроме того, замену устройств PCI тоже допустимо производить на лету. Помимо этого, данная модель характеризуется наличием универсальных программно-аппаратных средств Intel Server Management, представляющих собой мощные инструменты внутреннего (in-band) и внешнего (out-band) мониторинга и управления сервером.
В качестве коммутатора в разработанной конструкции применено 8-портовое решение SANbox 5200. Его использование дает возможность масштабирования до 64 подключений без дополнительного порта для межкоммутаторных соединений, производительность FibreChannel 10 Gbps и централизованное управление. Масштабируемость и быстродействие модульного коммутатора наращиваются по мере необходимости.
SANbox 5200 поддерживает трафик между коммутаторами, серверами и хранилищами со скоростью 2 Gbps и масштабируется от 4, 8, 12 и 16 до 64 портов в одном стеке. Функция NDCLA (non-disruptive code load and activation) позволяет добавлять, изменять или удалять свойства, не прерывая работу сети хранения данных.
Это один из первых FC-коммутаторов, конфигурировать и зонировать который можно, используя простые программы-мастера (wizard). ПО SANsurfer Management Suite упрощает управление стеками, помогая пользователям установить, конфигурировать, контролировать, диагностировать и осуществлять обновление при помощи одного приложения с простым графическим интерфейсом.
В качестве подсистемы хранения данных в кластер включены два высокоемких накопителя, выполненных по технологии SAN (Storage Area Network). Базовая конфигурация рассчитана на объем не менее 3,7 TВ, но при необходимости возможно расширение.
Каждое хранилище обеспечивает независимый аппаратно-программный мониторинг всех компонентов, контролируя состояние накопителей, источников питания, частоту вращения вентиляторов, температурный режим во всех модулях, своевременно информируя оператора о критических ситуациях, требующих вмешательства. Практически все модули могут быть заменены без остановки системы, в режиме hot plug.
Типология задач кластеризации[править]
Типы входных данныхправить
- Признаковое описание объектов. Каждый объект описывается набором своих характеристик, называемых признаками (англ. features). Признаки могут быть как числовыми, так и категориальными;
- Матрица расстояний между объектами. Каждый объект описывается расстоянием до всех объектов из обучающей выборки.
Вычисление матрицы расстояний по признаковому описанию объектов может быть выполнено бесконечным числом способов в
зависимости от определения метрики между объектами. Выбор метрики зависит от обучающей выборки и поставленной задачи.
Цели кластеризацииправить
Классификация объектов. Попытка понять зависимости между объектами путем выявления их кластерной структуры. Разбиение выборки на группы схожих объектов упрощает дальнейшую обработку данных и принятие решений, позволяет применить к каждому кластеру свой метод анализа (стратегия «разделяй и властвуй»). В данном случае стремятся уменьшить число кластеров для выявления наиболее общих закономерностей;
Сжатие данных. Можно сократить размер исходной выборки, взяв один или несколько наиболее типичных представителей каждого кластера
Здесь важно наиболее точно очертить границы каждого кластера, их количество не является важным критерием;
Обнаружение новизны (обнаружение шума). Выделение объектов, которые не подходят по критериям ни в один кластер
Обнаруженные объекты в дальнейшем обрабатывают отдельно.
Методы кластеризацииправить
- Графовые алгоритмы кластеризации. Наиболее примитивный класс алгоритмов. В настоящее время практически не применяется на практике;
- Вероятностные алгоритмы кластеризации. Каждый объект из обучающей выборки относится к каждому из кластеров с определенной степенью вероятности:
- Иерархические алгоритмы кластеризации. Упорядочивание данных путем создания иерархии вложенных кластеров;
- Алгоритм -средних (англ. -means). Итеративный алгоритм, основанный на минимизации суммарного квадратичного отклонения точек кластеров от центров этих кластеров;
- Распространение похожести (англ. affinity propagation). Распространяет сообщения о похожести между парами объектов для выбора типичных представителей каждого кластера;
- Сдвиг среднего значения (англ. mean shift). Выбирает центроиды кластеров в областях с наибольшей плотностью;
- Спектральная кластеризация (англ. spectral clustering). Использует собственные значения матрицы расстояний для понижения размерности перед использованием других методов кластеризации;
- Основанная на плотности пространственная кластеризация для приложений с шумами (англ. Density-based spatial clustering of applications with noise, DBSCAN). Алгоритм группирует в один кластер точки в области с высокой плотностью. Одиноко расположенные точки помечает как шум.
Сравнение алгоритмов кластеризации из пакета scikit-learn
Кластер как метод критического мышления
На что ориентирована современная система образования? На повышение самостоятельности младшего школьника. Критическое мышление – это педагогическая технология, которая стимулирует интеллектуальное развитие учеников. Прием «кластер» в начальной школе – это один из его методов.
Критическое мышление проходит три стадии: вызов, осмысление, рефлексия.
Первый этап – стадия активизации. Происходит вовлечение всех учащихся в процесс. Его цель – воспроизведение уже имеющихся знаний по заданной теме, формирование ассоциативного ряда и постановка проблемных вопросов по теме. Фаза осмысления характеризуется организацией работы с информацией. Это может быть чтение материала в учебнике, обдумывание или анализ имеющихся фактов. Рефлексия – это стадия, когда полученные знания перерабатываются в ходе творческой деятельности, после чего делаются выводы.
Если взглянуть на эти три стадии с точки зрения традиционного урока, то становится очевидным, что они не являются принципиально новыми для учителей. Они присутствуют в большинстве случаев, только называются несколько иначе. «Вызов» в более привычном для учителя названии звучит как «актуализация знаний» или «введение в проблему». «Осмысление» — это не что иное, как «открытие нового знания учащимися». В свою очередь, «рефлексия» совпадает с этапом закрепления новых знаний и их первичной проверкой.
В чем же различие? Что принципиально нового несет технология «составление кластера» в начальной школе?
Элемент необычности и новизны заключается в методических приемах, ориентируемых на создание условий свободного развития каждой личности. Каждая стадия урока подразумевает использование своих методических приемов. Их существует достаточно много: кластер, инсерт, синквейн, таблица толстых и тонких вопросов, зигзаг, «шесть шляп мышления», верные и неверные утверждения и прочие.
Пример кластера в истории
Занимаясь историей, можно составлять кластеры, которые помогут лучше понять изучаемую тему. Выделив ключевое слово, можно составить к нему несколько подходящих определений. В приведенной ниже схеме такое ключевое слово показано красным шрифтом.

В красных кружках определяем блоки второго уровня, от которых уже идут тематические определения.
Для кластера в истории основным определением является выделение смысловых единиц текста и их графическое оформление в определенном порядке.
Создавать кластеры при изучении истории можно на любую тему. Данная технология поможет понять изучаемую тему.
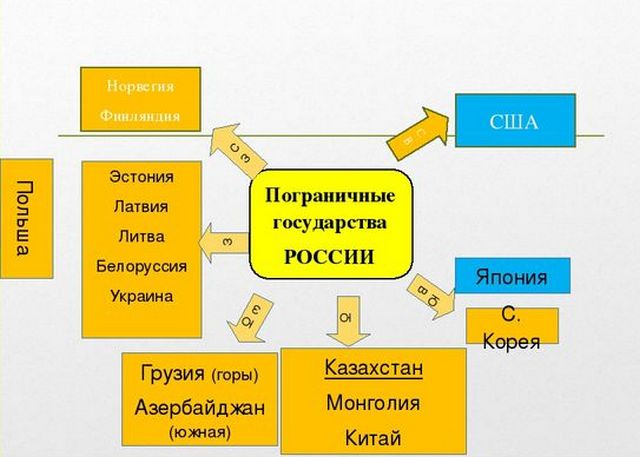
Использование кластеров характерно в большей степени для школьного обучения.
Уникальный татарстанский проект
Что касается господдержки кластеров, то здесь, по словам экспертов, иногда лучше не мешать. Точнее, уменьшать бюрократическую нагрузку. Причем, юридически кластер можно и не оформлять. Регистрация нужна, чтобы это сообщество получало государственную поддержку. Например, сейчас по программе Минпромторга РФ кластеры могут получать до 50 процентов компенсации технологических затрат (патентование, обучение персонала, исследовательские работы и так далее). По словам Альберта Гайфуллина, это очень эффективный рычаг и механизм.
Однако до сих пор не решена проблема с коммуникацией. Зачастую участники одного кластера не знают, что какие-то собственные задачи могут решить с помощью коллег по кластеру. Татарстан собирается решить это.
— На самом деле проект исторический. Уже посажено первое зерно. И мы впервые в истории республики собрали за одним столом всех руководителей кластеров и представителей Министерства экономики. И провели установочную сессию. На следующем этапе начнем прорабатывать дорожную карту и механизмы сотрудничества, где есть и крупный бизнес, и средний, и малый.
Это будет региональная площадка, которую мы можем в будущем, на определенных условиях, масштабировать. В течение 1 года мы хотим утвердить механизмы работы, сформировать штат, состав, найти финансового партнера, — рассказал Гайфуллин.
По предварительному плану, система должна заработать к весне 2019 года.
Официальные партнеры:
Юля Красникова, фото Олега Тихонова, видео Камиля Исмаилова
МероприятияOnline-конференцииПромышленность Татарстан
Заключение
Педагогический прием «составление кластера» предполагает создание некоторой схемы, обобщающей имеющиеся факты и дающей ответы на сформулированные в начале работы вопросы. Занятия с использованием метода кластеров дают обучающимся возможность обозначить свою позицию на видение того или иного вопроса, проявить свои лучшие стороны, свободно заниматься креативной деятельностью. При использовании нетрадиционных методов обучения в образовательном процессе, у детей повышается уровень мотивации, они учатся сотрудничать и в полной мере испытывают чувство собственного достоинства.







 Adblock
Adblock