Пишем примитивный и никому не нужный компилятор
Содержание:
- Содержание:
- Содержание
- составление
- Примечание по байт-коду
- Работа с памятью
- Примечания
- Типы интерпретаторов
- Типы интерпретаторов
- Токенизация
- Разница между компилятором и интерпретатором
- Интерпретатор C / C++ Ch Embeddable (стандартная версия)
- Типы интерпретаторов
- Определение компилятора
- Типы интерпретаторов
- Достоинства и недостатки интерпретаторов
- Достоинства и недостатки интерпретаторов
- Типы интерпретаторов
- Вывод
Содержание:
Компилятор против интерпретатора
И компилятор, и интерпретатор в основном служат одной цели. Они переводят один уровень языка на другой. Компилятор преобразует инструкции высокого уровня в машинный язык, в то время как интерпретатор преобразует инструкцию высокого уровня в некоторую промежуточную форму, и после этого инструкция выполняется.
Компилятор
Компилятор определяется как компьютерная программа, которая используется для преобразования инструкций или языка высокого уровня в форму, понятную компьютеру. Поскольку компьютер может понимать только двоичные числа, для заполнения пробела используется компилятор, иначе человеку было бы сложно найти информацию в форме 0 и 1.
Раньше компиляторы были простыми программами, которые использовались для преобразования символов в биты. Программы также были очень простыми и содержали ряд шагов, вручную переведенных в данные. Однако это был очень трудоемкий процесс. Итак, некоторые детали были запрограммированы или автоматизированы. Это сформировало первый компилятор.
Более сложные компиляторы создаются с использованием более простых. С каждой новой версией добавляется больше правил и создается более естественная языковая среда для человека-программиста. Программы-компиляторы развиваются таким образом, что упрощает их использование.
Существуют определенные компиляторы для определенных языков или задач. Компрессоры могут быть многоэтапными или многоступенчатыми. Первый проход может преобразовать язык высокого уровня в язык, более близкий к компьютерному. Затем последующие проходы могут преобразовать его в финальную стадию для выполнения.
Переводчик
Программы, созданные на языках высокого уровня, могут выполняться двумя разными способами. Первый — это использование компилятора, а второй — использование интерпретатора. Обучение или язык высокого уровня переводится в промежуточный с помощью переводчика. Преимущество использования интерпретатора заключается в том, что инструкция высокого уровня не проходит стадию компиляции, что может занять много времени. Итак, с помощью интерпретатора программа высокого уровня выполняется напрямую. По этой причине некоторые программисты используют интерпретаторы при создании небольших участков, поскольку это экономит время.
Почти все языки программирования высокого уровня имеют компиляторы и интерпретаторы. Но некоторые языки, такие как LISP и BASIC, разработаны таким образом, что программы, созданные с их помощью, выполняются интерпретатором.
|
Разница между компилятором и интерпретатором • Компилятор преобразует инструкцию высокого уровня в машинный язык, а интерпретатор преобразует инструкцию высокого уровня в промежуточную форму. • Перед выполнением вся программа выполняется компилятором, тогда как после перевода первой строки ее выполняет интерпретатор и так далее. • Список ошибок создается компилятором после процесса компиляции, а интерпретатор прекращает перевод после первой ошибки. • Независимый исполняемый файл создается компилятором, тогда как интерпретатор требуется интерпретируемой программе каждый раз. |
Содержание
Компилятор — это переводчик, который преобразует исходный язык (язык высокого уровня) в объектный язык (машинный язык). В отличие от компилятора, интерпретатор — это программа, имитирующая выполнение программ, написанных на исходном языке. Еще одно различие между компилятором и интерпретатором заключается в том, что компилятор преобразует всю программу за один раз, а интерпретатор преобразует программу, беря за раз одну строку.
Очевидно, что восприятие человека и электронного устройства, такого как компьютер, отличается. Люди могут понимать что угодно на естественных языках, но компьютер — нет. Компьютеру нужен переводчик для преобразования языков, написанных в удобочитаемой форме, в машиночитаемую форму.
Компилятор и интерпретатор — это типы языкового переводчика. Что такое языковой переводчик? Этот вопрос может возникнуть у вас в голове.
Языковой переводчик — это программное обеспечение, которое переводит программы с исходного языка в удобочитаемой форме в эквивалентную программу на объектном языке. Исходный язык обычно является языком программирования высокого уровня, а объектный язык — обычно машинным языком реального компьютера.
составление
Для написания программы необходимо выполнить следующие действия:
- Редактировать программу
- Скомпилируйте программу в файлы машинного кода.
- Свяжите файлы машинного кода в работающую программу (также известную как exe).
- Отладка или запуск программы
Для некоторых языков, таких как Turbo Pascal и Delphi, шаги 2 и 3 объединены.
Файлы машинного кода — это автономные модули машинного кода, которые требуют связывания вместе для создания окончательной программы. Причиной наличия отдельных файлов машинного кода является эффективность; компиляторы должны только перекомпилировать исходный код, который изменился. Файлы машинного кода из неизмененных модулей используются повторно. Это известно как создание приложения. Если вы хотите перекомпилировать и пересобрать весь исходный код, это называется сборкой.
Связывание — это технически сложный процесс, когда все вызовы функций между различными модулями связаны друг с другом, ячейки памяти выделяются для переменных, а весь код размещается в памяти, а затем записывается на диск как законченная программа.
Это часто более медленный шаг, чем компиляция, поскольку все файлы машинного кода должны быть считаны в память и связаны друг с другом.
Примечание по байт-коду
Как и в случае с машинным кодом, не все компьютеры понимают байт-код. Чтобы интерпретировать его на машиночитаемый язык, необходимо промежуточное ПО, такое как виртуальная машина, или движок (например, Javascript V8). По этой причине браузеры могут выполнять этот байт-код из интерпретатора во время вышеупомянутых 5-ти стадий с помощью движков JavaScript.
В результате возникает следующий вопрос:
Является ли JavaScript интерпретируемым языком?
Да, но не совсем. На ранних этапах JavaScript Брендан Айк создал движок JavaScript ‘SpiderMonkey’. У движка был интерпретатор, который говорил браузеру, что нужно делать. Сейчас есть не только интерпретаторы, но и компиляторы, а код не только интерпретируется, но и компилируется для оптимизации. Технически все зависит от реализации.
- Прототипирование для Vue(Opens in a new browser tab)
- Как не лажать с JavaScript. Часть 1
- JavaScript async/await: что хорошего, в чём опасность и как применять?
Перевод статьи Mano lingam: JavaScript: Under the Hood
Работа с памятью
Почти все знают, что языки типа Java/Python очень удобные, т.к. автоматизируют сборку мусора. Это значит, что если вы выделите память под объект (например, массив), а затем этот объект станет вам не нужен — то виртуальная машина сама освободит память. Например, в следующей программе при вызове функции создается новый объект , который после завершения работы функции становится недоступен — это и есть мусор. В языке C++ такие объекты уничтожаются в момент выхода из функции, а в Java, Python и многих других интерпретируемых языках — они живут до тех пор, пока свободная память не кончится:
public class Main {
public static void say(String name) {
String text = "hello " + name;
System.out.println(text);
}
public static void main(String[] args) {
say("Bob");
}
}
Опытный программист знает что существуют различные типы сборщиков и запуская программу можно указать какой тип сборщика использовать.
Система управления памятью занимается не только сборкой мусора, но также:
- выделением памяти — так, чтобы избежать фрагментации;
- запросом новых страниц памяти у операционной системы и возвратом освобожденных;
- обнаружением мусора (объектов, которые можно удалить). При этом используется анализ доступности (подсчет ссылок в многопоточной среде не работает).
Вся эта дополнительная работа выполняется неявно в момент выполнения вашей программы и, естественно, тормозит. Обычно для сборки памяти необходима полная остановка вашей программы (всех потоков), поэтому когда память кончится — программа «зависнет» пока не закончит сборку. Память требуется не только для объектов в вашей программе, но и для работы самой JVM, в частности, объектами являются и потребляют память: загруженные классы; код, скомпилированный с помощью JIT; оптимизированный код.
Выше отмечалось, что компиляция и оптимизация могут выполняться многократно во время работы программы, в зависимости от того, как эта программа используется. После оптимизации в памяти оказывается не только оптимизированный код, но и изначальный — на случай если программа начнет использоваться по другому сценарию и потребуется «откат оптимизации». Поэтому модуль оптимизации занимается также «деоптимизацией». Следовательно, от менеджера памяти зависят все элементы интерпретатора и загрузчик.
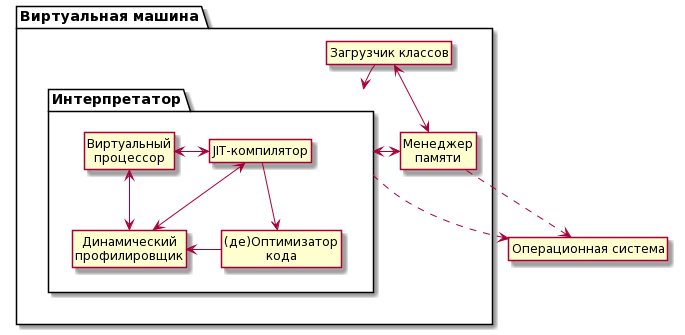
Как и все остальные темы, работу с памятью в виртуальных машинах мы рассмотрим более подробно в следующих статьях. На текущем этапе должно быть понятно, что:
- помимо вашей программы, виртуальная машина выполняет очень много дополнительной работы;
- виртуальная машина имеет опции запуска, позволяющие управлять этой работой.
Понимая некоторые детали устройства виртуальной машины можно не только обоснованно выбрать опции для нее, но и писать более эффективный код. Это лучше чем заучить наизусть сотни рекомендаций типа:
String bad = new String("Slower");
String good = "Faster";
Дополнительная литература по теме:
- Тюнинг JVM на примере одного проекта. URL: https://habr.com/en/company/luxoft/blog/174231/
- Java Bytecode Fundamentals. URL: https://habr.com/ru/post/111456/
- PGO: уход и кормление. URL: https://vk.com/for_programmer?w=wall-105242702_801
- Как работает JS: о внутреннем устройстве V8 и оптимизации кода. URL: https://habr.com/ru/company/ruvds/blog/337460/
- Martinsen, J. K., Grahn, H. (2010). An alternative optimization technique for JavaScript engines. Presented at the Third Swedish Workshop on Multi-Core Computing (MCC-10), Göteborg: Chalmers University of Technology. Retrieved from http://urn.kb.se/resolve?urn=urn:nbn:se:bth-7688
- Введение в технологии виртуализации.
Примечания
- Кочергин В. И. interpreter // Большой англо-русский толковый научно-технический словарь компьютерных информационных технологий и радиоэлектроники. — 2016. — ISBN 978-5-7511-2332-1.
- Интерпретатор // Математический энциклопедический словарь / Гл. ред. Прохоров Ю. В.. — М.: Советская энциклопедия, 1988. — С. 820. — 847 с.
- ГОСТ 19781-83; СТ ИСО 2382/7-77 // Вычислительная техника. Терминология: Справочное пособие. Выпуск 1 / Рецензент канд. техн. наук Ю. П. Селиванов. — М.: Издательство стандартов, 1989. — 168 с. — 55 000 экз. — ISBN 5-7050-0155-X.
- Першиков В. И., Савинков В. М. Толковый словарь по информатике / Рецензенты: канд. физ.-мат. наук А. С. Марков и д-р физ.-мат. наук И. В. Поттосин. — М.: Финансы и статистика, 1991. — 543 с. — 50 000 экз. — ISBN 5-279-00367-0.
- Борковский А. Б. Англо-русский словарь по программированию и информатике (с толкованиями). — М.: Русский язык, 1990. — 335 с. — 50 050 (доп,) экз. — ISBN 5-200-01169-3.
- Толковый словарь по вычислительным системам = Dictionary of Computing / Под ред. В. Иллингуорта и др.: Пер. с англ. А. К. Белоцкого и др.; Под ред. Е. К. Масловского. — М.: Машиностроение, 1990. — 560 с. — 70 000 (доп,) экз. — ISBN 5-217-00617-X (СССР), ISBN 0-19-853913-4 (Великобритания).
Типы интерпретаторов
Простой интерпретатор анализирует и тут же выполняет (собственно интерпретация) программу покомандно (или построчно), по мере поступления её исходного кода на вход интерпретатора. Достоинством такого подхода является мгновенная реакция. Недостаток — такой интерпретатор обнаруживает ошибки в тексте программы только при попытке выполнения команды (или строки) с ошибкой.
Интерпретатор компилирующего типа — это система из компилятора, переводящего исходный код программы в промежуточное представление, например, в байт-код или p-код, и собственно интерпретатора, который выполняет полученный промежуточный код (так называемая виртуальная машина). Достоинством таких систем является большее быстродействие выполнения программ (за счёт выноса анализа исходного кода в отдельный, разовый проход, и минимизации этого анализа в интерпретаторе). Недостатки — большее требование к ресурсам и требование на корректность исходного кода. Применяется в таких языках, как Java, PHP, Tcl, Perl, REXX (сохраняется результат парсинга исходного кода), а также в различных СУБД.
В случае разделения интерпретатора компилирующего типа на компоненты получаются компилятор языка и простой интерпретатор с минимизированным анализом исходного кода. Причём исходный код для такого интерпретатора не обязательно должен иметь текстовый формат или быть байт-кодом, который понимает только данный интерпретатор, это может быть машинный код какой-то существующей аппаратной платформы. К примеру, виртуальные машины вроде QEMU, Bochs, VMware включают в себя интерпретаторы машинного кода процессоров семейства x86.
Некоторые интерпретаторы (например, для языков Лисп, Scheme, Python, Бейсик и других) могут работать в режиме диалога или так называемого цикла чтения-вычисления-печати (англ. read-eval-print loop, REPL). В таком режиме интерпретатор считывает законченную конструкцию языка (например, s-expression в языке Лисп), выполняет её, печатает результаты, после чего переходит к ожиданию ввода пользователем следующей конструкции.
Уникальным является язык Forth, который способен работать как в режиме интерпретации, так и компиляции входных данных, позволяя переключаться между этими режимами в произвольный момент, как во время трансляции исходного кода, так и во время работы программ.
Следует также отметить, что режимы интерпретации можно найти не только в программном, но и аппаратном обеспечении. Так, многие микропроцессоры интерпретируют машинный код с помощью встроенных микропрограмм, а процессоры семейства x86, начиная с Pentium (например, на архитектуре Intel P6), во время исполнения машинного кода предварительно транслируют его во внутренний формат (в последовательность микроопераций).
Типы интерпретаторов
Простой интерпретатор анализирует и тут же выполняет (собственно интерпретация) программу покомандно (или построчно), по мере поступления её исходного кода на вход интерпретатора. Достоинством такого подхода является мгновенная реакция. Недостаток — такой интерпретатор обнаруживает ошибки в тексте программы только при попытке выполнения команды (или строки) с ошибкой.
Интерпретатор компилирующего типа — это система из компилятора, переводящего исходный код программы в промежуточное представление, например, в байт-код или p-код, и собственно интерпретатора, который выполняет полученный промежуточный код (так называемая виртуальная машина). Достоинством таких систем является большее быстродействие выполнения программ (за счёт выноса анализа исходного кода в отдельный, разовый проход, и минимизации этого анализа в интерпретаторе). Недостатки — большее требование к ресурсам и требование на корректность исходного кода. Применяется в таких языках, как Java, PHP, Tcl, Perl, REXX (сохраняется результат парсинга исходного кода), а также в различных СУБД.
В случае разделения интерпретатора компилирующего типа на компоненты получаются компилятор языка и простой интерпретатор с минимизированным анализом исходного кода. Причём исходный код для такого интерпретатора не обязательно должен иметь текстовый формат или быть байт-кодом, который понимает только данный интерпретатор, это может быть машинный код какой-то существующей аппаратной платформы. К примеру, виртуальные машины вроде QEMU, Bochs, VMware включают в себя интерпретаторы машинного кода процессоров семейства x86.
Некоторые интерпретаторы (например, для языков Лисп, Scheme, Python, Бейсик и других) могут работать в режиме диалога или так называемого цикла чтения-вычисления-печати (англ. read-eval-print loop, REPL). В таком режиме интерпретатор считывает законченную конструкцию языка (например, s-expression в языке Лисп), выполняет её, печатает результаты, после чего переходит к ожиданию ввода пользователем следующей конструкции.
Уникальным является язык Forth, который способен работать как в режиме интерпретации, так и компиляции входных данных, позволяя переключаться между этими режимами в произвольный момент, как во время трансляции исходного кода, так и во время работы программ.
Следует также отметить, что режимы интерпретации можно найти не только в программном, но и аппаратном обеспечении. Так, многие микропроцессоры интерпретируют машинный код с помощью встроенных микропрограмм, а процессоры семейства x86, начиная с Pentium (например, на архитектуре Intel P6), во время исполнения машинного кода предварительно транслируют его во внутренний формат (в последовательность микроопераций).
Токенизация
токенизируются
- Токенизация чисел
Числа преобразуются в двоичный вид, чтобы не преобразовывать их каждый раз, когда они встречаются в программе. Если числа встречаются только один раз, то рост производительности оказывается не таким большим, но в цикле с большим количеством вычислений это выгодно, потому что число уже представлено в виде, который может понять компьютер. - Пометка строк
Так как память ограничена, если в коде есть строка, которую можно использовать без изменений, то логично будет так и поступить. Например, может выводить «Hello, World» непосредственно из строки программы вместо выделения нового пространства, копирования строки и её вывода.
Чтобы упростить пропуск строк во время выполнения программы, мы также храним длину самой строки. - Поиск в таблице ключевых слов
Всё, что не является числом или строкой, может быть ключевым словом, поэтому нам нужно выполнять поиск по списку ключевых слов. Это тривиально на JavaScript, но совсем непросто на ассемблере!
После нахождения ключевого слова связанный с ним токен сохраняется в памяти программы (вместо всего ключевого слова целиком). В результате этого мы можем сэкономить много пространства, особенно когда команду типа можно сократить до одного байта! - Вычисление указателей на переменные
Имена переменных Retroputer BASIC значимы только до первых двух символов (на данный момент). Благодаря этому можно тривиальным образом искать переменную в массиве при помощи довольно простого математического выражения. Но даже в таком случае вычисления занимают время, поэтому было бы здорово, если бы нам не приходилось этого делать при встрече с переменной.
Retroputer BASIC будет вычислять индекс и хранить его вместе с именем переменной. Кроме имени переменной он также хранит длину переменной, чтобы ускорить выполнение программы. Это занимает большое количество пространства и не было бы хорошим решением для компьютеров с ограниченной памятью, но подходит для Retroputer BASIC.
Разница между компилятором и интерпретатором
Основание различия
Компилятор
Устный переводчик
Шаги программирования
Создайте программу.
Compile проанализирует или проанализирует все операторы языка на предмет их правильности. Если неверно, выдает ошибку
Если ошибок нет, компилятор преобразует исходный код в машинный код.
Он связывает разные файлы кода в исполняемую программу (известную как exe).
Запустить программу
Создать программу
Без связывания файлов или генерации машинного кода
Исходные операторы выполняются построчно ВО ВРЕМЯ выполнения
Преимущество Программный код уже переведен в машинный код. Таким образом, время выполнения кода меньше. Переводчиками проще пользоваться, особенно новичкам.
Недостаток Вы не можете изменить программу, не вернувшись к исходному коду. Интерпретируемые программы могут работать на компьютерах с соответствующим интерпретатором.
Машинный код Хранить машинный язык как машинный код на диске Никакого сохранения машинного кода.
Продолжительность Скомпилированный код работает быстрее Интерпретируемый код работает медленнее
Модель Он основан на языковой модели перевода ссылок-загрузки. Он основан на методе интерпретации.
Генерация программы Создает программу вывода (в виде exe), которую можно запускать независимо от исходной программы. Не генерировать программу вывода. Таким образом, они оценивают исходную программу каждый раз во время выполнения.
Исполнение Выполнение программы отделено от компиляции. Он выполняется только после того, как вся программа вывода скомпилирована. Выполнение программы является частью процесса интерпретации, поэтому оно выполняется построчно.
Требования к памяти Целевая программа выполняется независимо и не требует наличия компилятора в памяти. Во время устного перевода переводчик существует в памяти.
Лучше всего подходит для Ограничено конкретной целевой машиной и не может быть перенесено. C и C ++ — самые популярные языки программирования, использующие модель компиляции
Для веб-сред, где важно время загрузки. Из-за того, что выполнен исчерпывающий анализ, компиляции требуется относительно больше времени для компиляции даже небольшого кода, который нельзя запускать несколько раз
В таких случаях лучше переводчики.
Оптимизация кода Компилятор видит весь код заранее. Следовательно, они выполняют множество оптимизаций, которые ускоряют работу кода. Интерпретаторы видят код построчно, поэтому оптимизации не так надежны, как компиляторы.
Динамический набор текста Сложно реализовать, поскольку компиляторы не могут предсказать, что произойдет во время очереди. Переводимые языки поддерживают динамический ввод
использование Лучше всего подходит для производственной среды. Он лучше всего подходит для программы и среды разработки.
Выполнение ошибки Компилятор отображает все ошибки и предупреждения во время компиляции. Следовательно, вы не можете запустить программу без исправления ошибок. Интерпретатор читает один оператор и показывает ошибку, если таковая имеется. Вы должны исправить ошибку, чтобы интерпретировать следующую строку.
Вход Требуется целая программа Требуется всего одна строчка кода.
Выход Compliers генерирует промежуточный код machnie. Интерпретатор никогда не генерирует какой-либо промежуточный мачный код.
Ошибки Отображать все ошибки после компиляции одновременно. Отображает все ошибки каждой строки одну за другой.
Соответствующие языки программирования C, C ++, C #, Scala, Java используют компилятор. PHP, Perl, Ruby используют интерпретатор.
Интерпретатор C / C++ Ch Embeddable (стандартная версия)
Интерпретатор C / C++, поддерживающий стандарт ISO 1990 C (C90), основные функции C99, классы C++, а также расширения к языку С, такие как вложенные функции, строковый тип и т. д. Он может быть встроен в другие приложения и аппаратные средства, использоваться в качестве языка сценариев. Код C / C++ интерпретируется напрямую без компиляции промежуточного кода. Поскольку этот интерпретатор поддерживает Linux, Windows, MacOS X, Solaris и HP-UX, созданный вами код можно перенести на любую из этих платформ. Стандартная версия бесплатна для личного, академического и коммерческого использования. Для загрузки пакета необходимо зарегистрироваться.
Типы интерпретаторов
Простой интерпретатор анализирует и тут же выполняет (собственно интерпретация) программу покомандно (или построчно), по мере поступления её исходного кода на вход интерпретатора. Достоинством такого подхода является мгновенная реакция. Недостаток — такой интерпретатор обнаруживает ошибки в тексте программы только при попытке выполнения команды (или строки) с ошибкой.
Интерпретатор компилирующего типа — это система из компилятора, переводящего исходный код программы в промежуточное представление, например, в байт-код или p-код, и собственно интерпретатора, который выполняет полученный промежуточный код (так называемая виртуальная машина). Достоинством таких систем является большее быстродействие выполнения программ (за счёт выноса анализа исходного кода в отдельный, разовый проход, и минимизации этого анализа в интерпретаторе). Недостатки — большее требование к ресурсам и требование на корректность исходного кода. Применяется в таких языках, как Java, PHP, Tcl, Perl, REXX (сохраняется результат парсинга исходного кода), а также в различных СУБД.
В случае разделения интерпретатора компилирующего типа на компоненты получаются компилятор языка и простой интерпретатор с минимизированным анализом исходного кода. Причём исходный код для такого интерпретатора не обязательно должен иметь текстовый формат или быть байт-кодом, который понимает только данный интерпретатор, это может быть машинный код какой-то существующей аппаратной платформы. К примеру, виртуальные машины вроде QEMU, Bochs, VMware включают в себя интерпретаторы машинного кода процессоров семейства x86.
Некоторые интерпретаторы (например, для языков Лисп, Scheme, Python, Бейсик и других) могут работать в режиме диалога или так называемого цикла чтения-вычисления-печати (англ. read-eval-print loop, REPL). В таком режиме интерпретатор считывает законченную конструкцию языка (например, s-expression в языке Лисп), выполняет её, печатает результаты, после чего переходит к ожиданию ввода пользователем следующей конструкции.
Уникальным является язык Forth, который способен работать как в режиме интерпретации, так и компиляции входных данных, позволяя переключаться между этими режимами в произвольный момент, как во время трансляции исходного кода, так и во время работы программ.
Следует также отметить, что режимы интерпретации можно найти не только в программном, но и аппаратном обеспечении. Так, многие микропроцессоры интерпретируют машинный код с помощью встроенных микропрограмм, а процессоры семейства x86, начиная с Pentium (например, на архитектуре Intel P6), во время исполнения машинного кода предварительно транслируют его во внутренний формат (в последовательность микроопераций).
Определение компилятора
Компилятор — это программа, которая читает программу, написанную на языке высокого уровня, преобразует ее в машинный или язык низкого уровня и сообщает об ошибках, присутствующих в программе. Он преобразует весь исходный код за один раз или может потребовать несколько проходов для этого, но, наконец, пользователь получает скомпилированный код, готовый к выполнению.
Компилятор работает по фазам; различные этапы можно сгруппировать в две части:
- Фаза анализа компилятора также называется внешним интерфейсом, в котором программа делится на основные составные части и проверяет грамматику, семантику и синтаксис кода, после чего генерируется промежуточный код. Фаза анализа включает в себя лексический анализатор, семантический анализатор и синтаксический анализатор.
- Фаза синтеза компилятора также известен как серверная часть, в которой оптимизируется промежуточный код и генерируется целевой код. Фаза синтеза включает оптимизатор кода и генератор кода.
Типы интерпретаторов
Простой интерпретатор анализирует и тут же выполняет (собственно интерпретация) программу покомандно (или построчно), по мере поступления её исходного кода на вход интерпретатора. Достоинством такого подхода является мгновенная реакция. Недостаток — такой интерпретатор обнаруживает ошибки в тексте программы только при попытке выполнения команды (или строки) с ошибкой.
Интерпретатор компилирующего типа — это система из компилятора, переводящего исходный код программы в промежуточное представление, например, в байт-код или p-код, и собственно интерпретатора, который выполняет полученный промежуточный код (так называемая виртуальная машина). Достоинством таких систем является большее быстродействие выполнения программ (за счёт выноса анализа исходного кода в отдельный, разовый проход, и минимизации этого анализа в интерпретаторе). Недостатки — большее требование к ресурсам и требование на корректность исходного кода. Применяется в таких языках, как Java, PHP, Tcl, Perl, REXX (сохраняется результат парсинга исходного кода), а также в различных СУБД.
В случае разделения интерпретатора компилирующего типа на компоненты получаются компилятор языка и простой интерпретатор с минимизированным анализом исходного кода. Причём исходный код для такого интерпретатора не обязательно должен иметь текстовый формат или быть байт-кодом, который понимает только данный интерпретатор, это может быть машинный код какой-то существующей аппаратной платформы. К примеру, виртуальные машины вроде QEMU, Bochs, VMware включают в себя интерпретаторы машинного кода процессоров семейства x86.
Некоторые интерпретаторы (например, для языков Лисп, Scheme, Python, Бейсик и других) могут работать в режиме диалога или так называемого цикла чтения-вычисления-печати (англ. read-eval-print loop, REPL). В таком режиме интерпретатор считывает законченную конструкцию языка (например, s-expression в языке Лисп), выполняет её, печатает результаты, после чего переходит к ожиданию ввода пользователем следующей конструкции.
Уникальным является язык Forth, который способен работать как в режиме интерпретации, так и компиляции входных данных, позволяя переключаться между этими режимами в произвольный момент, как во время трансляции исходного кода, так и во время работы программ.
Следует также отметить, что режимы интерпретации можно найти не только в программном, но и аппаратном обеспечении. Так, многие микропроцессоры интерпретируют машинный код с помощью встроенных микропрограмм, а процессоры семейства x86, начиная с Pentium (например, на архитектуре Intel P6), во время исполнения машинного кода предварительно транслируют его во внутренний формат (в последовательность микроопераций).
Достоинства и недостатки интерпретаторов
Достоинства
- Бо́льшая переносимость интерпретируемых программ — программа будет работать на любой платформе, на которой есть соответствующий интерпретатор.
- Как правило, более совершенные и наглядные средства диагностики ошибок в исходных кодах.
- Меньшие размеры кода по сравнению с машинным кодом, полученным после обычных компиляторов.
Недостатки
- Интерпретируемая программа не может выполняться отдельно без программы-интепретатора. Сам интерпретатор при этом может быть очень компактным.
- Интерпретируемая программа выполняется медленнее, поскольку промежуточный анализ исходного кода и планирование его выполнения требуют дополнительного времени в сравнении с непосредственным исполнением машинного кода, в который мог бы быть скомпилирован исходный код.
- Практически отсутствует оптимизация кода, что приводит к дополнительным потерям в скорости работы интерпретируемых программ.
Достоинства и недостатки интерпретаторов
Достоинства
- Большая переносимость интерпретируемых программ — программа будет работать на любой платформе, на которой есть соответствующий интерпретатор.
- Как правило, более совершенные и наглядные средства диагностики ошибок в исходных кодах.
- Меньшие размеры кода по сравнению с машинным кодом, полученным после обычных компиляторов.
Недостатки
- Интерпретируемая программа не может выполняться отдельно без программы-интерпретатора. Сам интерпретатор при этом может быть очень компактным.
- Интерпретируемая программа выполняется медленнее, поскольку промежуточный анализ исходного кода и планирование его выполнения требуют дополнительного времени в сравнении с непосредственным исполнением машинного кода, в который мог бы быть скомпилирован исходный код.
- Практически отсутствует оптимизация кода, что приводит к дополнительным потерям в скорости работы интерпретируемых программ.
Типы интерпретаторов
Простой интерпретатор анализирует и тут же выполняет (собственно интерпретация) программу покомандно (или построчно), по мере поступления её исходного кода на вход интерпретатора. Достоинством такого подхода является мгновенная реакция. Недостаток — такой интерпретатор обнаруживает ошибки в тексте программы только при попытке выполнения команды (или строки) с ошибкой.
Интерпретатор компилирующего типа — это система из компилятора, переводящего исходный код программы в промежуточное представление, например, в байт-код или p-код, и собственно интерпретатора, который выполняет полученный промежуточный код (так называемая виртуальная машина). Достоинством таких систем является большее быстродействие выполнения программ (за счёт выноса анализа исходного кода в отдельный, разовый проход, и минимизации этого анализа в интерпретаторе). Недостатки — большее требование к ресурсам и требование на корректность исходного кода. Применяется в таких языках, как Java, PHP, Tcl, Perl, REXX (сохраняется результат парсинга исходного кода), а также в различных СУБД.
В случае разделения интерпретатора компилирующего типа на компоненты получаются компилятор языка и простой интерпретатор с минимизированным анализом исходного кода. Причём ] для такого интерпретатора не обязательно должен иметь текстовый формат или быть байт-кодом, который понимает только данный интерпретатор, это может быть машинный код какой-то существующей аппаратной платформы. К примеру, виртуальные машины вроде QEMU, Bochs, VMware включают в себя интерпретаторы машинного кода процессоров семейства x86.
Некоторые интерпретаторы (например, для языков Лисп, Scheme, Python, Бейсик и других) могут работать в режиме диалога или так называемого цикла чтения-вычисления-печати (англ. read-eval-print loop, REPL). В таком режиме интерпретатор считывает законченную конструкцию языка (например, s-expression в языке Лисп), выполняет её, печатает результаты, после чего переходит к ожиданию ввода пользователем следующей конструкции.
Уникальным является язык Forth, который способен работать как в режиме интерпретации, так и компиляции входных данных, позволяя переключаться между этими режимами в произвольный момент, как во время трансляции исходного кода, так и во время работы программ.
Следует также отметить, что режимы интерпретации можно найти не только в программном, но и аппаратном обеспечении. Так, многие микропроцессоры интерпретируют машинный код с помощью встроенных микропрограмм, а процессоры семейства x86, начиная с Pentium (например, на архитектуре Intel P6), во время исполнения машинного кода предварительно транслируют его во внутренний формат (в последовательность микроопераций).
Вывод
И компилятор, и интерпретатор предназначены для выполнения одной и той же работы, но различаются по рабочей процедуре. Компилятор принимает исходный код агрегированным образом, тогда как интерпретатор принимает составные части исходного кода, то есть оператор за оператором.
Хотя и компилятор, и интерпретатор имеют определенные преимущества и недостатки, например, интерпретируемые языки считаются кроссплатформенными, то есть код переносимый. В отличие от компилятора, ему также не нужно предварительно компилировать инструкции, что позволяет сэкономить время. Скомпилированные языки быстрее в процессе компиляции.







 Adblock
Adblock